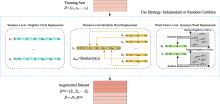
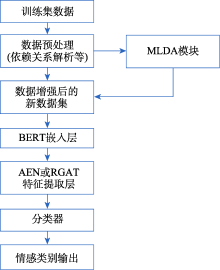
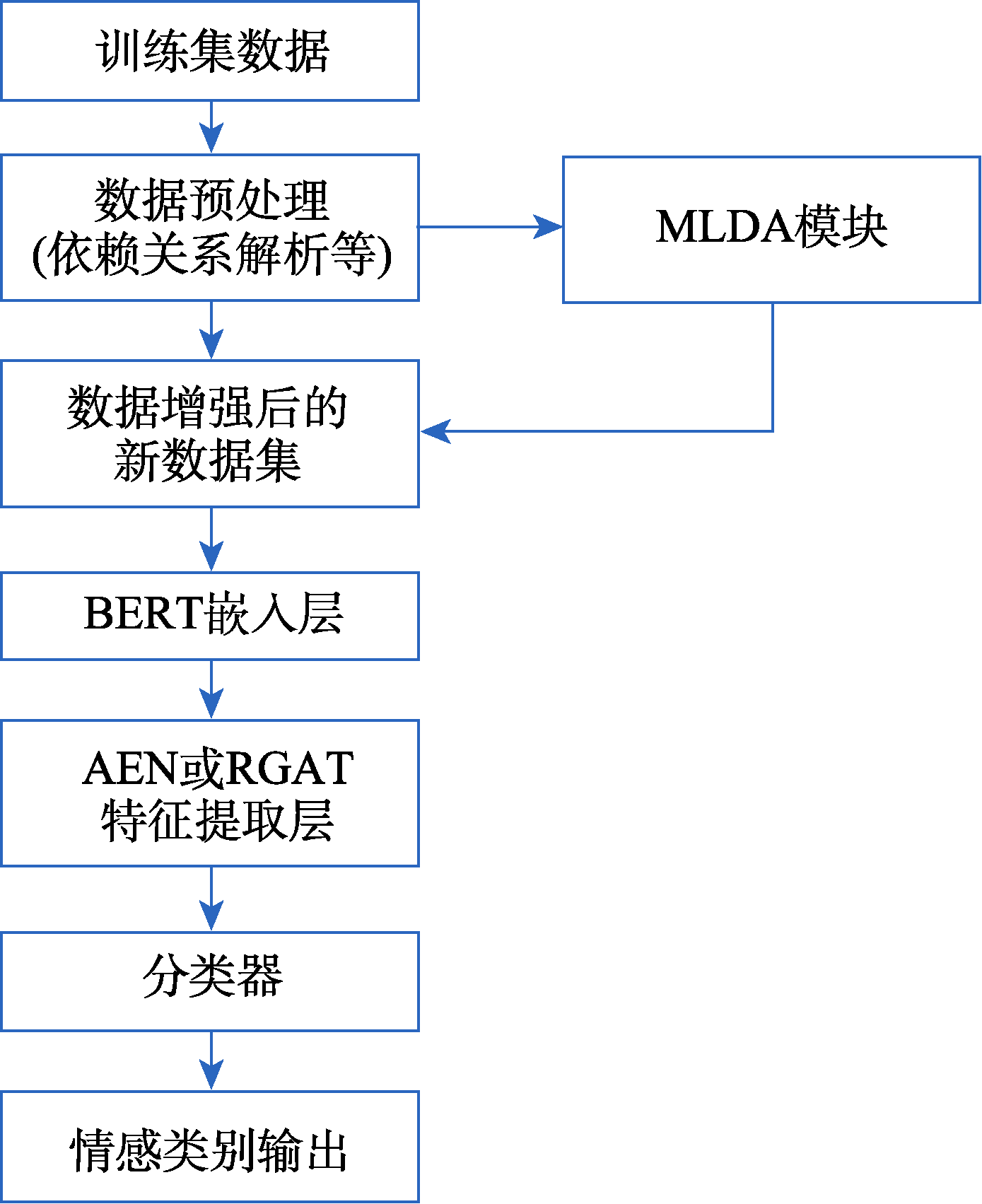
| [1] |
THET T T, NA J C, KHOO C S. Aspect-based sentiment analysis of movie reviews on discussion boards[J]. Journal of Information Science, 2010, 36(6): 823-848.
doi: 10.1177/0165551510388123
|
| [2] |
DEVLIN J, CHANG MINGWEI, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]// Proc of the Conference of the North American Chapter of the Association for Computational Linguistics: Language Technologies, 2019: 4171-4186.
|
| [3] |
WANG A, SINGH A, MICHAEL J, et al. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding[C]// Proc of the EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 2018: 353-355.
|
| [4] |
XIE Q Z, DAI Z H, EDUARD H, et al. Unsupervised data augmentation for consistency training[J]. Advances in Neural Information Processing Systems, 2020, 33: 6256-6268.
|
| [5] |
张严, 李天瑞. 面向评论的方面级情感分析综述[J]. 计算机科学, 2020, 47(6): 200-206.
|
| [6] |
PONTIKI M, GALANIS D, PAPAGEORGIOU H, et al. Semeval-2014 task 4: Aspect based sentiment analysis[C]// International Workshop on Semantic Evaluation, 2014: 19-30.
|
| [7] |
XU H, LIU B, SHU L, et al. BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis[C]// Proc of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019: 2324-2335.
|
| [8] |
ZHANG X, ZHAO J B, YAN L C. Character-level convolutional networks for text classification[J]. Advances in neural information processing systems, 2015, 28: 649-657.
|
| [9] |
ZHANG Y, CHEN G G, YU D, et al. Highway long short-term memory rnns for distant speech recognition[C]// IEEE International Conference on Acoustics.IEEE, 2016: 5755-5759.
|
| [10] |
LONGPRE S, WANG YU, DUBOIS C. How Effective is Task-Agnostic Data Augmentation for Pretrained Transformers?[C]// Findings of the Association for Computational Linguistics: EMNLP 2020, 2020: 4401-4411.
|
| [11] |
WEI J, ZOU K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks[C]// Proc of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, 2019:6382-6388.
|
| [12] |
KANG D, KHOT T, SABHARWAL A, et al. AdvEntuRe: Adversarial Training for Textual Entailment with Knowledge-Guided Examples[C]// Proc of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers), 2018: 2418-2428.
|
| [13] |
WANG K, SHEN W Z, YANG Y Y, et al. Relational Graph Attention Network for Aspect-based Sentiment Analysis[C]// Proc of the 58th Annual Meeting of the Association for Computational Linguistics, 2020: 3229-3238.
|
| [14] |
WANG Y Q, HUANG M L, ZHAO L, et al. Attention-based lstm for aspect-level sentiment classification[C]// Proc of the conference on empirical methods in natural language processing, 2016: 606-615.
|
| [15] |
SONG Y W, WANG J H, JIANG T, et al. Attentional Encoder Network for Targeted Sentiment Classification[J]. arXive-prints, 2019: 1902.09314.
|
| [16] |
HUANG B X, KATHLEEN M C. Syntax-Aware Aspect Level Sentiment Classifification with Graph Attention Networks[C]// Proc of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019: 5472-5480.
|
| [17] |
PENNINGTON J, SOCHER R, MANNING C D. Glove: Global vectors for word representation[C]// Proc of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014: 1532-1543.
|
| [18] |
SHORTEN C, KHOSHGOFTAAR T M. A survey on image data augmentation for deep learning[J]. Journal of big data, 2019, 6(1): 1-48.
doi: 10.1186/s40537-018-0162-3
|
| [19] |
LI B H, HOU Y T, CHE W X. Data augmentation approaches in natural language processing: A survey[J]. AI Open, 2022, 3:71-90.
doi: 10.1016/j.aiopen.2022.03.001
|
| [20] |
MILLER G A. WordNet: a lexical database for English[J]. Communications of the ACM, 1995, 38(11): 39-41.
|
| [21] |
SUN L C, XIA C Y, YIN W p, et al. Mixup-Transformer: Dynamic Data Augmentation for NLP Tasks[C]// Proc of the 28th International Conference on Computational Linguistics, 2020: 3436-3440.
|
| [22] |
TOMAS M, KAI C, GREG C, et al. Efficient estimation of word representations in vector space[J/OL]. CoRR, 2013: abs/1301.3781.
|
| [23] |
LIU S S, LEE K, LEE I. Document-level multi-topic sentiment classification of Email data with BiLSTM and data augmentation[J]. Knowledge-Based Systems, 2020: 197(4):489-499.
|
| [24] |
WANG Y W, YANG D Y. That’s so annoying!!!: A lexical and frame-semantic embedding based data augmentation approach to automatic categorization of annoying behaviors using petpeeve tweets[C]// Proc of the Conference on empirical methods in natural language processing, 2015: 2557-2563.
|
| [25] |
ZHANG W, DENG Y, Li X, et al. Aspect Sentiment Quad Prediction as Paraphrase Generation[C]// Proc of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021: 9209-9219.
|
| [26] |
TANG H, JI D H, LI C L, et al. Dependency graph enhanced dual-transformer structure for aspect-based sentiment classification[C]// Proc of the 58th Annual Meeting of the Association for Computational Linguistics, 2020: 6578-6588.
|
| [27] |
YANG H, LI K. Improving Implicit Sentiment Learning via Local Sentiment Aggregation[J]. arXiv preprint arXiv:2110.08604, 2021.
|
| [28] |
KAWIN E. How contextual are context tualized word representations? comparing the geometry of bert, elmo, and GPT-2 embeddings[C]// Proc of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019: 55-65.
|
| [29] |
CHEN T, SIMON K, MOHAMMAD N, et al. A simple framework for contrastive learning of visual representations[J]. Proceedings of Machine Learning Research(ICML), 2020: 1597-1607.
|
| [30] |
YAN Y M, LI R M, WANG S R, et al. Consert: A contrastive framework for self-supervised sentence representation transfer[J]. ACL/IJCNLP, 2021:5065-5075.
|
 ),刘渊2
),刘渊2